
This article has been originally published on Doctolib Engineering blog. Illustration by Bailey McGinn.
Every day at Doctolib comes with at least one release in production and we want each deployment to run smoothly for our millions of users, reaching zero downtime. Plenty of articles already describe how to deploy code or database changes, so we’ll focus on a less documented side of the equation: how to safely deploy changes related to the background jobs. When we deploy changes on our jobs we want all jobs to be processed without any error before, during and after the deployment.
At Doctolib, we use Unicorn as web servers and Resque as job workers.
Three steps in the deployment process that are critical to succeed in zero downtime jobs deployment:
- Migrate database (if necessary)
- Restart web workers in succession
- Restart job workers in succession
What could go wrong?
Let’s assume that the N code base is the current code base running in production before the deployment, and the N+1 code base is the one we are deploying.
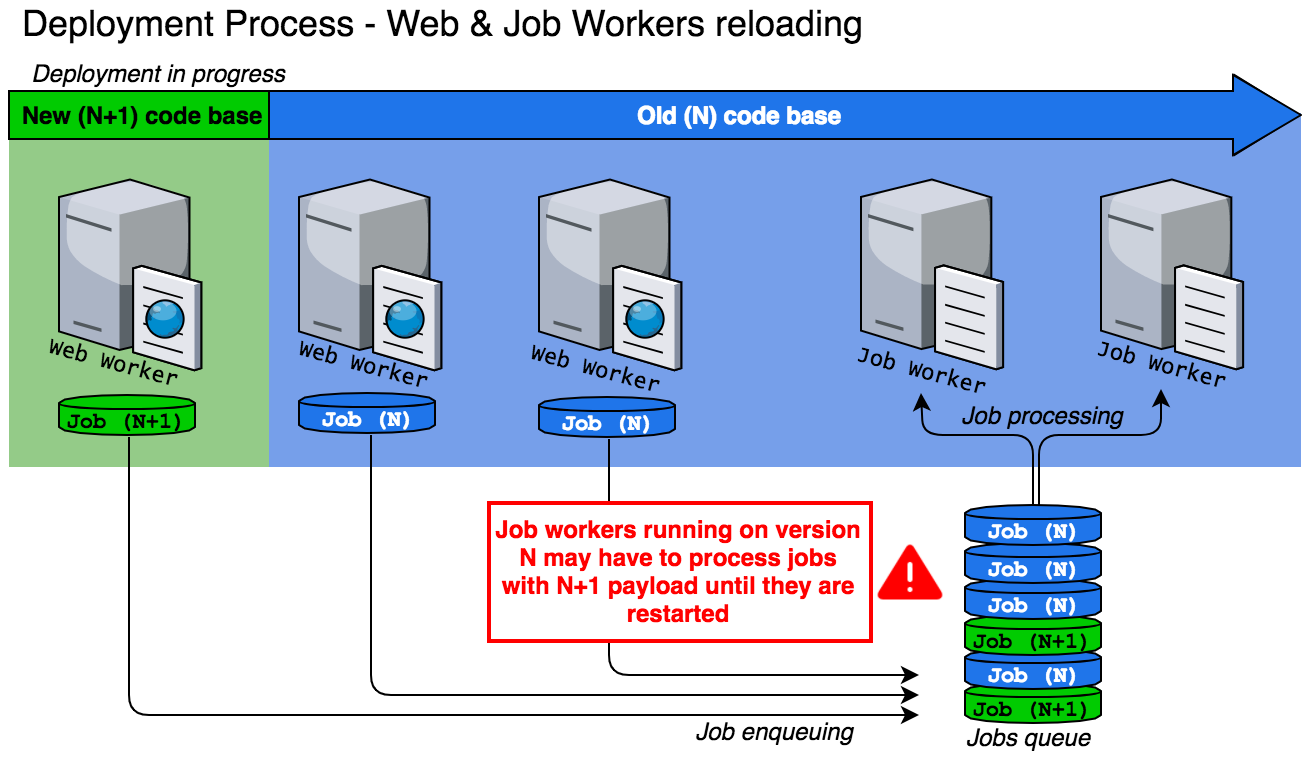
Case 1 — Deployment in progress
The first problem you could face takes place during the restart of web workers and before the restart of jobs workers. The web workers (running on the N+1 code base) enqueue jobs with N+1 payload to jobs workers running on N code base.
Case 2 — Deployment almost finished
Second problem: jobs with N payload could have been enqueued and still be processed after restarting the jobs workers that are now running on N+1 code base.
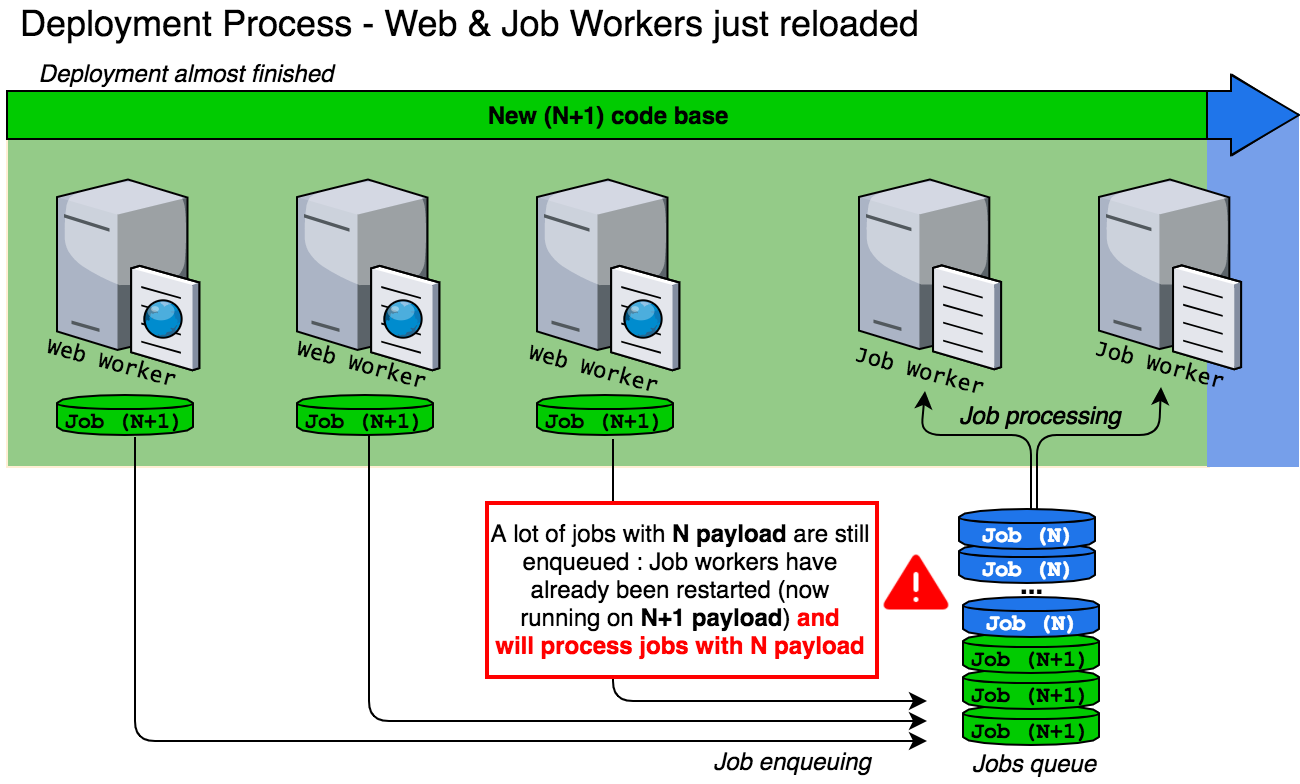
In both of these situations, jobs may fail because the two code bases are not compatible. This may arise when there is a change in the jobs payload, for example when:
- A new mandatory parameter is added into the N+1 code base that raises an exception when processed by the N code base,
- A job is deleted,
- A job is renamed, etc.
To summarize, you may encounter a problem as soon as one of these 3 elements is not in the same version as the two others:
- Code sending jobs
- Jobs payload
- Code processing jobs
Simplified reproduction of the problem
Let’s assume this is the code of a job running in production:
# N code base
# Payload example: { id: 42, message: ‘hello!’ }
class UserConfirmationJob < ActiveJob::Base
def perform(id, message)
User.find(id).send_confirmation(message)
end
end
And we want to add a new parameter:
# N+1 code base
# Payload example: { id: 42, message: ‘Hello!’, date: ‘2017–12–24’ }
class UserConfirmationJob < ActiveJob::Base
def perform(id, message, date)
User.find(id).send_confirmation(message, date)
end
end
This is what will happen during deployment if the new job’s code base is deployed as above:
- In the beginning, jobs are enqueued with N payload and are processed by job workers running on N code base.
- During and after restarting the web workers, jobs are enqueued with N+1 payload and are processed by job workers running on N code base (case 1).The jobs will fail: ArgumentError: wrong number of arguments (given 3, expected 2).
- After the restart of job workers, some jobs enqueued with N payload may remain and will be processed by job workers running on N+1 code base(case 2).The jobs will fail: ArgumentError: wrong number of arguments (given 2, expected 3).
A wild card issue appeared: quick and dirty solution
Case 1 — Deployment in progress
If a job with N+1 payload raises an error after being processed by a worker running on N code base, there is a chance that a simple replay will fix the problem. Wait for the deployment to be over, and retry the job. As we use Resque, it’s possible to use Resque web interface to resolve a small amount of small failed jobs. Otherwise, the failed jobs can be replayed from a Rails console.
Case 2 — Deployment almost finished
When the opposite occurs, if a job with N payload raises an error after being processed by a worker running on N+1 code base, it can’t be replayed. The best solution is to rollback the deployment, replay the failing jobs, and deploy the new code again. Pay attention to the version of the workers and the jobs: the workers need to process the jobs of the same version.
But there is a better way!
How to deploy safely?
You have to ensure that N+1 payloads are compatible with N payloads.
The best case scenario would be to have non-breaking changes, however, in cases when you must deploy a breaking change, you should split it into several non-breaking changes, and deploy them one after another.
Let’s apply this to our previous example. Instead of deploying the entire change, we will deploy this transitional version:
class UserConfirmationJob < ActiveJob::Base
def perform(id, message, date = nil)
if date
User.find(id).send_confirmation(message, date)
else
User.find(id).send_confirmation(message)
end
end
end
With this temporary version, we handle the two problematic cases:
- When a job enqueued with a N+1 payload is processed by a job worker running on N code base (if clause),
- When a job enqueued with a N payload is processed by a job worker running on N+1 code base (else clause).
Shortly after the deployment, we only have jobs enqueued with a N+1 payload processed by jobs workers running on N+1 code base. Our elseclause is now useless: we can deploy the definitive version of our change:
class UserConfirmationJob < ActiveJob::Base
def perform(id, message, date)
User.find(id).send_confirmation(message, date)
end
end
And voilà, the changes have been deployed without any error during deployment!This example is related to the addition of a parameter, but a similar approach can be used for other breaking changes:Delete code that is enqueuing the job (not the job itself)DeployThe job is not enqueued anymore: delete it, and deploy againWhen a job is renamed (e.g. from OldJob to NewJob):Create a new job NewJob that is a copy of (or a reference to) OldJob.
Keep OldJob as is, and don’t change the code that is enqueuing the job.DeployChange the code that is enqueuing the job to use NewJob.
Don’t delete OldJob.DeployOldJob is not used anymore: delete it, and deploy againThe cases you will face may look different, but the solution is always something similar to the above.How do you know your code will break workers?Each time you change a job’s code, simply looking at the difference between old and new code and knowing that this problem can happen, helps to detect 80% of potential problems.Six eyes are better than two: at Doctolib we perform, as a minimum, two code reviews for each Pull Request.
The tips discussed in this article are not limited to jobs. When upgrading an API or a web service, you may encounter the same problem of backward compatibility: it is possible to integrate the recommendations above into other areas of application.